Einleitend
Im letzen Beitrag habe ich dir gezeigt, wie man in der Cloud mit den Azure Cognitive Services – hier die Custom Vision API – ganz einfach ein eigenes Machine learning Modell, das ein Postauto erkennt, erstellen kann. Nun ist es an der Zeit, etwas mit dem Modell an zu fangen.
Wenn du mit den Möglichkeiten der Custom Vision API experimentiert hast, wirst du festgestellt haben, dass es wirklich ein mächtiger Service ist. …Klar! Cloud! Aber was ist, wenn du nun eine Anwendung bauen möchtest, die nicht immer auf die Cloud zugreifen kann. So wie ich es in meiner Haupt-Story mit dem Postauto habe (falls du dich nicht erinnerst, kannst du hier nachlesen).
Was in meinem Postauto Szenario mit hinein spielt, ist die sporadische Internetanbindung. Meine smarte Security Cam Lösung ist nicht ganz in voller Reichweite zu meinem WLAN. Ich benötigte daher eine Lösung, die ein Postauto eben nicht in der Cloud erkennt, sonder auf einem Device (on the edge).
Und darum soll es in diesem Beitrag gehen. Du wirst heute das Modell, dass du erstellt hast, auf deinem PC laufen lassen – ganz ohne Cloud.
In einem der folgenden Beiträge werde ich dir dann zeigen, wie du das Ganze auf ein Gerät zum Laufen bringst, in meinem Fall der Jetson Nano von Nvidia. Legen wir los!

Setup
Um das ML Modell lokal auf deinem PC laufen zu lassen, benötigst du nicht viel. Hier ist die Shopping list für dich:
- Docker Desktop
- Visual Studio Code (VS Code)
Fangen wir also mit den notwendigen Installationen an. Die Reihenfolge ist nicht entscheidend.
- Zuerst installierst du bitte Docker Desktop.
Um es auch auf Linux zum Laufen zu bewegen, kannst du leider nicht über den bequemen Weg der Installation gehen. Hier habe ich aber zwei Links, die dir helfen können (Docker Docs und Heise.de) - Jetzt installierst du VS Code, falls du diesen herausragenden Editor noch nicht auf deinem System hast.
Setup VSCode für den optimalen Einsatz
Wenn du alles soweit erfolgreich installiert und konfiguriert hast, können wir loslegen. Um eine gute Arbeitsumgebung zu haben, schlage ich dir vor, VSCode so einzurichten, dass du alles, was wir benötigen, aus diesem Tool heraus bedienen kannst.
In VS Code gibt es die Möglichkeit, Erweiterungen für den Editor zu laden und damit reichhaltige Funktionen dazu zu gewinnen. Wir benötigen hier Docker Container und Python Extensions. Wenn du aber schon dabei bist… installiere noch die Azure Tools, sowie Azure IoT Tools (Damit greifst du schon für einen der nächsten Beiträge vor)




Wenn du die Python-Erweiterung installierst, beachte bitte die Installationsanweisung. Es muss zusätzlich noch Python installiert werden, falls du es noch nicht drauf hast.
Download des ML-Modells
An diesem Punkt sollte deine „Entwicklungsumgebung“ eingerichtet sein und wir können uns nun auf die eigentliche Arbeit konzentrieren.
Microsoft hat hier über die Zeit hinweg viel auf Community und Customer Feedback reagiert und erlaubt es dem User sein Modell in unterschiedlichen Formaten herunter zu laden. Das wollen wir nutzen und unser Modell als Container lokal betreiben.
Dazu gehst du bitte in das Custom Vision Portal. Dort wählst du dein Projekt aus und klickst im Menü oben auf Performance.

Gleich darunter befindet sich der „Export“ Button, den du bitte auch anklickst.

Im erscheinenden Menü werden dir verschieden Optionen angeboten. Du kannst dein Modell für die App-Entwicklung unter iOS bzw. Android herunterladen, aber auch für Windows und speziell für das Vision AI Dev Kit, das man ebenfalls als smarte Security Cam her nehmen kann.
Die für uns interessante Option ist „Dockerfile“. Damit lädst du ein Paket herunter, in dem unter anderem Python Code, das ML Modell und ein Dockerfile zu finden ist.
Für unser Projekt wählst du die Linux Konfiguration herunter. Der Button, den du klickst, heißt beim ersten Klick „Export“ – dies bereitet dein Modell für den Export auf. Wenn es paketiert ist – das dauert wirklich nur ein oder zwei Sekunden – nennt sich der Button „Download“ und du kannst fortfahren.

Da du vermutlich neugierig auf den Inhalt bist, folgt hier die Beschreibung dessen:

Das Dockerfile.
Wenn du noch nicht mit Docker Containern zu tun hattest, ist jetzt vielleicht der richtige Moment, dich etwas ein zu arbeiten. Dokumentation
Wie du erkennen kannst, braucht es Python als Interpreter, das Modul numpy für das Arbeiten mit Array, Tensorflow für das Arbeiten mit dem ML-Modell, flask, das als Webserver für die Rest API dient und pillow zur Verarbeitung von Bildern. Der Port für die Rest API ist auf 80 festgelegt und die Inhalte des Ordners App werden in den Container kopiert.
Zusätzlich findest du zwei Verzeichnisse. Der Ordner „azureml“ ist für uns heute nicht so interessant. Er dient zur Erstellung eines AzureML Services; gehosted und verwaltet durch MLOps in Azure. Du könntest diesen auch Löschen, falls er dich hier stört.
Interessanter jedoch ist der Ordner „app“. In diesem befindet sich die komplette Logik für das Aufsetzen einer Web API und dem Erkennen von Objekten.
Die Datei app.py beinhaltet die Logik der Applikation (WebServer aufrufen, Warten auf Bild, Abfragen des ML Modells und Rückgabe des Ergebnisses als JSON). Die Dateien Predict.py und object_detection.py übernehmen die ML-Arbeit.

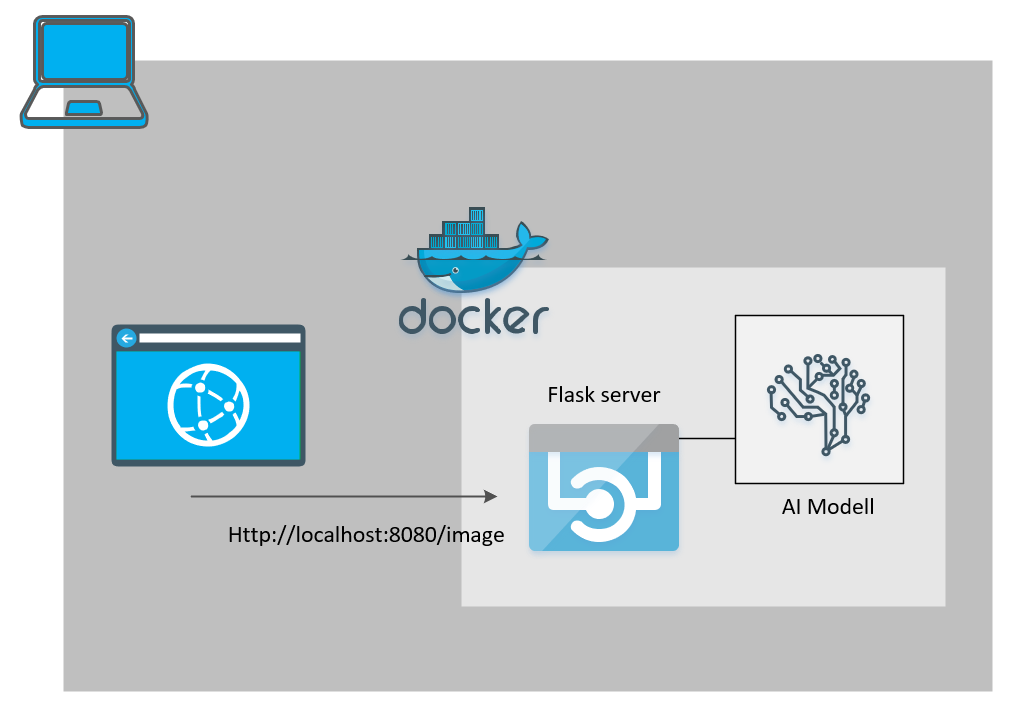
Das Bild zeigt, wie die Applikation als Docker Container funktionieren wird.
Über einen Rest Call auf, zum Beispiel, localhost:8080 kann man ein Bild an den Container übergeben (Postman ist dein Freund). Dieses wird dann per Tensorflow „analysiert“ und als Json-Antwort zurückgegeben.
Go local…
Als nächstes bauen wir das Image.
Wenn du VSCode so im Einsatz hast, wie ich es am Anfang beschrieben hatte, kannst du nun per Rechtsklick auf das Dockerfile ein Image erstellen lassen.

In VSCode musst du dann oben den Imagenamen eingeben. Entweder gibst du mit Repository an oder verwendest einen lokalen (zBsp: meinRepository.io/postcardetection:latest oder postcardetection:latest).
In Powershell kannst du auch gern mit dem Befehl
docker build --rm -f "Pfad\zum\Dockerfile" -t dein-image-name:latest "."
deinen Build starten.

Der Buildprozess dauert etwas. Dabei kannst du verfolgen, was alles installiert und eingerichtet wird.
Nach erfolgreichem Build kannst du deine „App“ verwenden.

In VSCode wählst du in der Activity Bar links Docker aus. Dann suchst du dein Image aus. Mit Rechtsklick auf das „latest“-Image kannst du im Kontextmenü „Run“ auswählen, um das Dockerimage als Container laufen zu lassen.
-> per Powershell auch wieder über
docker run --rm -d -p 80:80/tcp dein-image-name:latest
Den Port passt du deinen Änderungen natürlich an!


Wenn der Container läuft, kannst du das Tool deiner Wahl nutzen, um den Rest Call an den Container ab zu setzen. Ich benutze hier Postman, aber auch Powershell kann helfen (nur könntest du Schwierigkeiten haben das Bild im entsprechenden Body des Invoke-Rest Commands mit zu schicken – viel Spaß beim tüffteln).

Der Rest Call ist ein Post – den du einstellen musst. Die Adresse, wenn du den Port im Dockerfile nicht verändert hast, ist 80. Die Adresse lautet dann bei dir vermutlich http://localhost:80/image oder natürlich http://localhost/image .
In Postman wechselst du in die Body Einstellungen und dort auf binary. Dadurch baust du einen Rest Call der Binärdaten, also ein Bild, im Body an die Url überträgt.

Klicke auf den Button „Select file“ und suche dir ein Bild mit einem Postauto in einer Szene aus. (Ich habe dafür einmal das Bild aus der Highlevelarchitektur meines Intro-Blogposts gewählt).

Wenn du in Postman nun auf Send klickst, wird dein Bild, wie oben in der Funktionsübersicht, an den Container übertragen und ausgewertet. Als Reponse bekommst du das Ergebnis im Json Format.

Das Ergebnis meines Architekturbildes ist ein gefundenes Postauto, das mit einer Wahrscheinlichkeit von 81,7% erkannt wurde. Gleichzeitig bekommen wir auch die Boundingbox, also die Position im Bild, mitgeliefert. Das ist ein gutes Ergebnis! Das kleinere Postauto oben im Bild wird nicht erkannt, da es vermutlich einfach viel zu klein und damit zu „unscharf“ für den Detektor ist.
Um die Box in ein Bild einzumalen, müssen die Koordinaten [in Prozent] (top, left, width, height) noch mit den Bildmaßen verrechnet werden, da bei der Detektion das Bild normalisiert wurde.
Beispiel: Wenn dein Bild eine Größe von 866×484 hat, dann bekommst du für
top: 484 * 0,565 ~ 274
left: 866 * 0,0775 ~ 67
width: 484 * 0,154 ~ 75
height: 866 * 0.115 ~ 100
Unser Rechteck, das wir zeichnen müssten, wäre also nach (x1,y1, x2,y2)
(67, 274, (67 + 75), (274 + 100) )
Damit hast du nun dein eigenes lokales Postauto-Erkennungssystem. Es ist sicherlich nicht besonders komfortabel mit den Rest Calls, aber wenn du nun etwas Programmiergeschick anwendest, kannst du sicher schnell eine schöne und elegante Lösung zaubern. Versuche es doch gern und teile mir dein Feedback als Kommentar unter dem Beitrag mit oder schreibe mir ne Mail. Ich freuen mich.